先进的区块链索引简化了数据检索,使开发人员能够更快、更高效地访问信息。
1.区块链数据结构的特点
与传统集中式数据库不同,区块链是一种分布式账本技术,可在多台计算机之间记录交易,确保没有单一实体掌控全局。由于数据存储在不同位置,即使部分网络节点出现故障或遭受攻击,数据依然安全可访问。
区块链技术具有透明性,允许网络参与者查看交易,并通过数据不可更改性增强安全性。数据存储在区块中,每个区块通过加密链接与前一个区块相连。任何篡改行为都会导致后续区块的加密链接发生变化,从而被轻易检测。
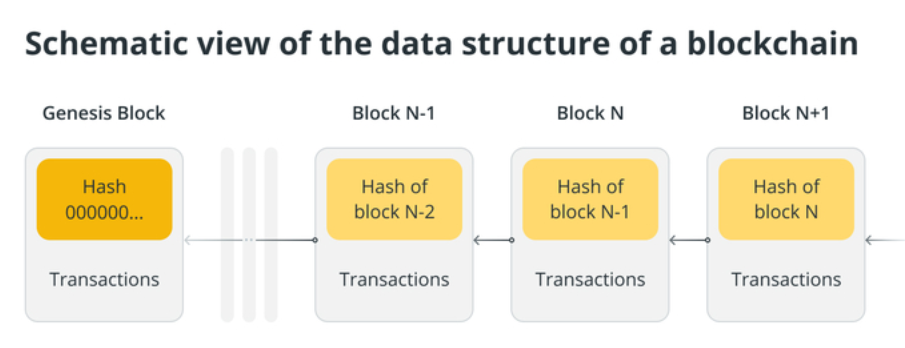
节点负责将数据转换为区块并添加到链中。维护完整区块链副本的节点有权验证交易。验证过程中,节点使用各种共识算法来确认交易并保持记录最新。验证后,交易被分组为区块并安全地添加到链中。
尽管区块链技术为数据存储提供了创新方法,但在数据查询和读取方面也带来了巨大挑战,需要采用全新的数据处理和查询方法。
2.区块链数据的处理和查询方式
在区块链网络中查询数据时,需要访问存储在多个节点上的分布式账本。与允许直接实时查询的传统数据库不同,区块链数据通常以只读方式查询。
用户向网络发送查询请求特定信息,节点则响应所需数据。由于区块链的分布式结构,可能需要多次连接才能确保数据的准确性和一致性。因此,区块链网络中的数据查询往往比传统数据库慢,因为需要从多个来源收集和验证数据。
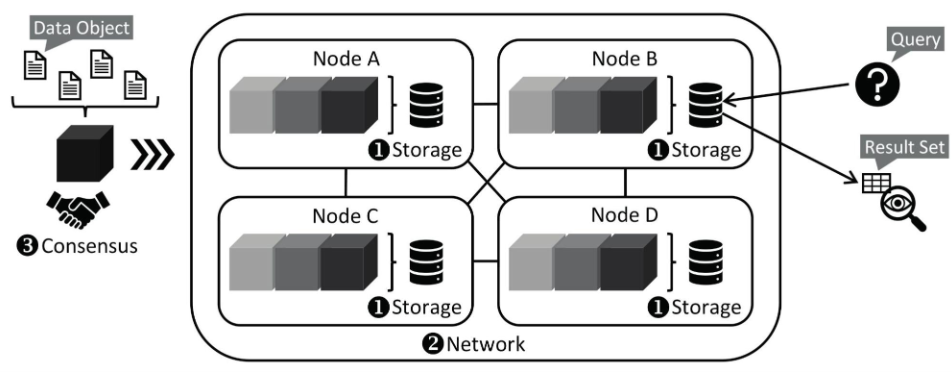
查询效率低下的另一个原因是区块链网络中数据的线性存储方式。查询特定数据可能需要检查多个区块,甚至逐个扫描整个链,这是一个耗时的过程。
为优化流程并提高查询性能,一些协议引入了高级索引方法。借助这些方法,去中心化应用程序(DApp)开发人员可以高效地索引和查询跨多个区块链网络的数据。
3.改进区块链数据处理和查询的方法
应用高级索引技术并优化数据检索过程可以提高区块链生态系统中的数据处理和查询性能。预先计算的索引和缓存常用数据等技术可以加快查询速度。通过更快地访问存储的数据,DApp开发人员可以在扫描数据时节省时间和成本。
SubQuery Network是一种去中心化数据索引和查询协议,为DApp开发人员提供了快速设置、管理和索引区块链数据的系统。该平台通过将数据处理负载分散到多个节点来提高数据查询和处理的速度。
DApp开发人员还可以利用SubQuery的软件开发工具包(SDK),该工具包旨在帮助导航区块链网络、收集数据并以优化格式呈现数据。SDK包含了开发人员创建和集成特定系统应用程序所需的工具、库和代码示例。
SubQuery通过企业级托管服务确保持续的数据处理和查询,并提供GraphQL订阅和自动历史记录跟踪等工具以提高效率。此外,SubQuery还提供远程过程调用(RPC)服务,允许开发人员将数据提交到区块链网络。
4.多链索引及其工作原理
多链索引通过提供单一兼容接口和统一的数据管理方法,消除了区块链网络中的低效率。开发人员无需专用的数据处理服务器,可以更专注于产品开发和用户体验。
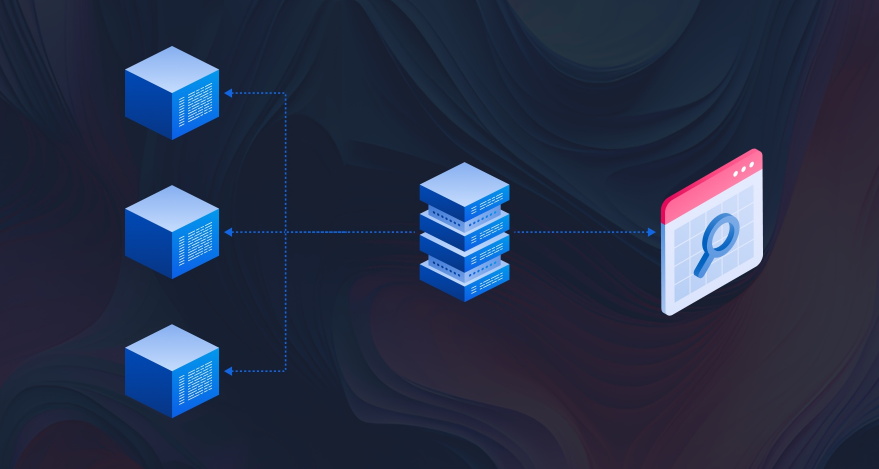
SubQuery简化了跨不同区块链网络索引和查询数据的过程,支持包括Polkadot、Cosmos、Avalanche和以太坊虚拟机(EVM)兼容链在内的多个区块链生态系统。开发人员可以处理包含相同数据架构和映射文件的单个SubQuery项目,以索引不同区块链网络中的数据。
5.互联网络对Web3开发者的好处
互联的基础设施使开发人员能够访问和集成跨多个区块链网络的数据,开发出能与不同区块链生态系统交互的DApp,提供更强大的功能和多功能性。
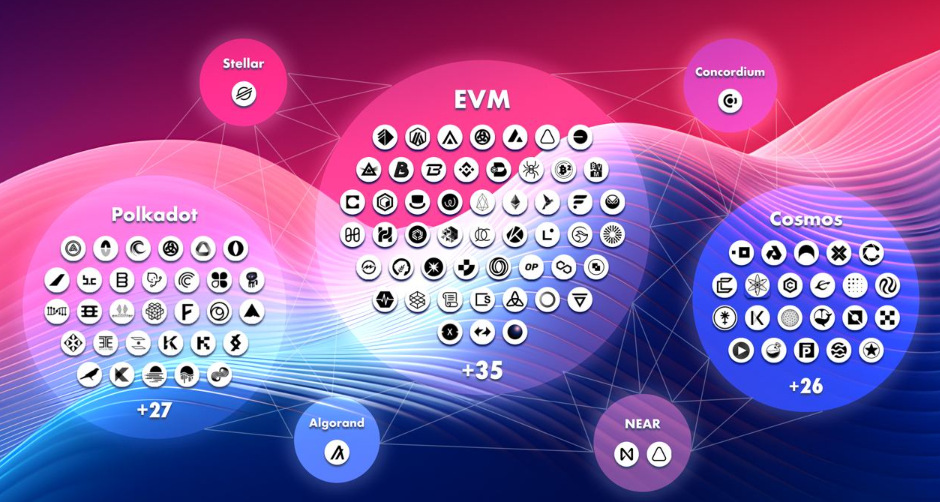
SubQuery支持200多个网络,提高了多链多样性。其去中心化结构使数据处理和查询能够分布在多个节点上,提高系统性能,避免传统系统中常见的瓶颈和单点故障。
通过使开发人员能够创建更复杂、数据密集型的应用程序,SubQuery鼓励区块链生态系统内的创新和增长。该平台还在GitHub上提供了一种简短的表单,为构建EVM第2层网络并需要测试网支持的开发人员提供快速、无摩擦的支持。